TL;DR
– Doubleword.ai ran all benchmarks from Artificial Analysis. Average lag between open-weight and closed-source LLMs sits at a flat level. Hasn’t moved.
– Coding’s the outlier: open models improved significantly on that specific index.
– Everything else is getting worse, not better. Some categories adding several months of gap per year.
– Projected parity date. The one that blew up on HN and r/LocalLLaMA. Came from ONE benchmark’s linear extrapolation. That’s it.
—
Last week a chart hit my feed. Open-weight LLMs catching up to closed models, full parity predicted for a future date. Points on Hacker News. Comments.
Developers screenshotting it for their roadmaps.
Infrastructure leads citing it in architecture reviews.
It was wrong.
Not lying. Just incomplete. There’s a difference.
Doubleword.ai dropped a counter-analysis recently. Most people sharing the original either didn’t see it or glossed over it.
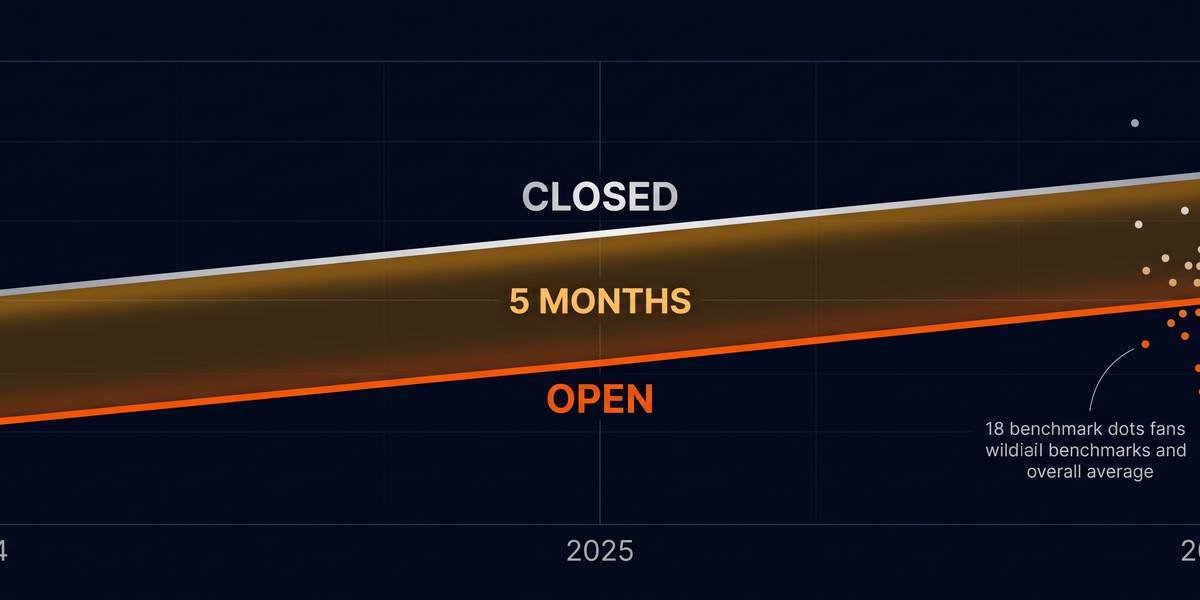
Their approach: pull all benchmarks from Artificial Analysis, measure the actual lag in months between open and closed models hitting the same performance level on each one.
The result should embarrass everyone who shared the original without reading further.
Flat. Line. At just under a consistent level.
Not closing. Not widening. Just sitting there.
Why One Benchmark Gets You a Viral Post, Not the Truth
Here’s what probably happened.
Someone grabbed a single Artificial Analysis benchmark.
Most likely the coding index. Slapped on a line of best fit, and extrapolated into the future. One line. One dataset. Linear projection.
That’s how you get a date that fits in a tweet.
The problem: benchmarks don’t behave.
They don’t all move in the same direction at the same speed.
Doubleword.ai did it properly. For each of the benchmarks, they plotted the gap in months over time, built box plots showing distribution across all benchmarks per month, then calculated the average gap and fit a line to that.
Flat. Consistent level.
For the entire observed period.
A recent model release didn’t close the gap then. Hasn’t budged since.
Another analysis ran independently.
Confirms it: gap was smallest around that release. And “since then the gap has been growing.” That’s not spin. That’s what the numbers show.
Coding Benchmarks Are an Outlier, Not the Pattern
Let me be fair here. The coding numbers are real.
The coding index improved significantly. That’s not nothing.
If you’re shipping code generation, completion, debugging — open-weight models are genuinely competitive right now.
Recent models show impressive scores on coding benchmarks. Those aren’t misprints. They’re just one slice.
Now look at the other benchmarks.
Doubleword.ai flags that most datasets show “a moderate increase over time in their gaps.” Not stable.
Growing. Open models still trail on complex tasks. Closed models hold a real lead on those.
Another analysis ran four major benchmarks independently. Their finding: significant lag, with a wide confidence interval. And here’s the part nobody wants to hear. A model’s publication date explains the variation in performance just as well as whether it’s open or closed weight.
Publication timing matters.
A model released later will often score better regardless of whether it’s open or closed. That’s not opinion. That’s in their methodology section.
What This Actually Means for Your Stack
If you’re running an agency or flying solo, here’s what this comes down to.
Open-weight makes sense today if your workload is coding-heavy, your context windows fit local models. And you’ve got the infra to run them.
The economics are real: no per-token billing, no rate limits, no vendor lock-in.
For a consulting shop billing hourly, controlling the runtime means reproducible outputs for client work. APIs don’t give you that week to week.
But if you’re building anything that leans on broad reasoning, multi-step agentic flows, biology, cybersecurity. The non-coding benchmarks — you’re buying closed-model time for the foreseeable future.
The lag isn’t zero.
On private benchmarks, the gap is significantly larger. The public-benchmark estimate is significantly underestimated.
That gap has a dollar figure.
Budgeting for open-weight inference while assuming parity with leading models on general tasks? Your capacity planning will be wrong. The model you’re running will trail the frontier by several months on at least some of your workloads.
When clients are paying for results, that matters.
Stop Anchoring on a Single Benchmark
The real issue isn’t open versus closed. It’s how the industry reads these things.
One benchmark trending the right way gets charted, shared, cited as proof of convergence. Other benchmarks showing stable or worsening gaps get skipped because they don’t fit the narrative.
Another analysis documents this pattern. A leading model sat noticeably above open alternatives through recent years. By the future date, the lead has “substantially narrowed” in some dimensions.
“Substantially narrowed” and “eliminated” are different words. Other implications for production.
If you’re making build-versus-buy calls, never trust a single benchmark. Never trust a linear extrapolation into the future from one trend line. The projected parity date is one dataset’s wishful projection, not a fact.
Doubleword.ai’s honest conclusion: this exercise “does suggest the difficulty of measuring LLM quality.” That’s the real takeaway.
The Practical Read
Open-source AI is improving. Coding proves it.
The gap on those tasks collapsed significantly.
But the average across the full benchmark set is consistent and isn’t moving.
The future date is one benchmark’s hope.
Not the industry’s consensus. And for the non-coding workloads. The ones running in production at most agencies. Gap: real and open.
If you’ve been building your roadmap around open weights reaching frontier parity by year-end, stress-test that assumption.
Run your actual workloads against what open models handle today.
Not what one extrapolated trend line promises for the future.
The lag won’t scare off everyone.
Some teams find the cost-control tradeoff worth it. But it should show up in capacity planning as a number, not a rumor.
Check the full benchmark set.
Not just the one that confirms what you want to be true.


