Claude Opus 4.7 Is Anthropic’s Riskiest Bet Yet
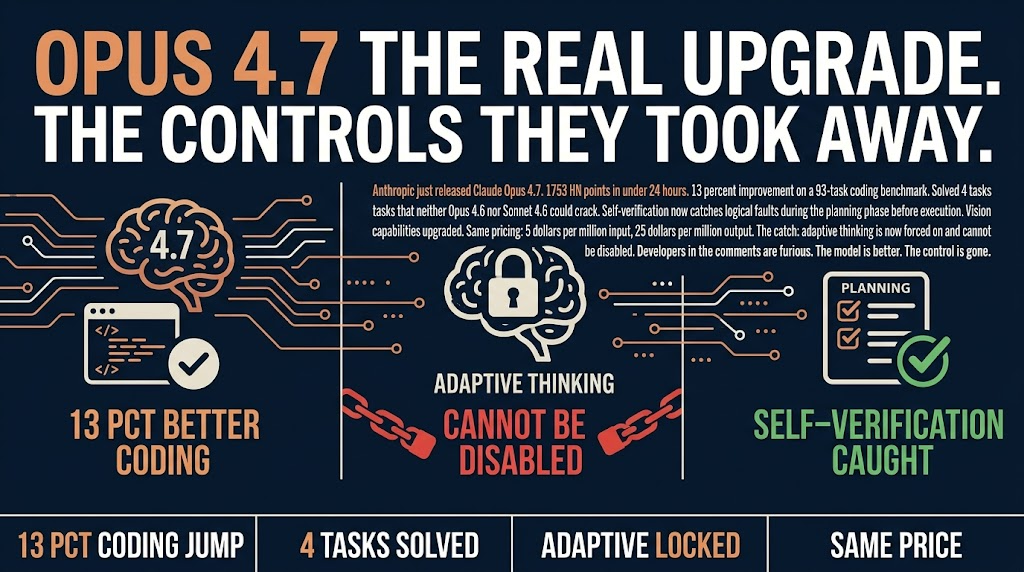
Anthropic just made a decision that will define how you run AI coding agents for the next year. Adaptive thinking, the feature power users have been debating for months, is now forced on. You cannot turn it off. That is the story that 1,260 HN commenters are arguing about.
The capability jump is real but narrow
Claude Opus 4.7 scores 13% better on coding benchmarks than its predecessor. It cracked four tasks that both Opus 4.6 and Sonnet 4.6 could not solve. These are real improvements. But here is the thing: benchmark jumps rarely translate directly to your workflow. The tasks that stumped earlier models are usually the hardest ones in the set, not the ones blocking your sprint.
The self-verification during planning is more interesting. The model now catches its own logical faults before executing code. This is new. For automation workflows that previously needed constant checking, this could mean fewer late-cycle surprises. Fewer bugs reaching production. Fewer iterations on code that seemed right but was fundamentally broken in approach.
For a solo operator or small team running AI agents without a senior developer watching every output, this is the part worth caring about. The model is doing more of the review work it used to punt to you.
The adaptive thinking trap
Their reasoning is probably that it produces better outcomes on average. The problem is that some workflows depend on predictable thinking time and disabling thinking budgets for simpler tasks. Anthropic is betting their way is right for everyone. That is a significant philosophical stance for a company whose competitive moat is developer goodwill.
On HN, the top comment threads are all about this. Developers with specific latency requirements, cost-sensitive automation pipelines, and agents that need deterministic behavior are frustrated. They traded control for capability. Whether that was the right call depends entirely on your use case.
For most teams, it probably does not matter. For the power users driving agentic workflow design, it might matter a lot.
The pricing story nobody is talking about
Anthropic kept pricing flat at $5 per million input tokens and $25 per million output tokens. Here is why that matters more than the benchmark score.
When a model thinks better and self-verifies, it generates fewer wasted output tokens on corrections and retries. For a thousand automation tasks running daily, that compounds into real savings. The model might be slower per task but more accurate, and accuracy is usually the expensive part.
Most coverage is focused on the capability jump. The real economic story is in the token efficiency.
Your efficiency window
Early adopters who restructure their automation loops around Opus 4.7 will have a three to six month advantage. But this assumes Anthropic’s vision for the model is the right one. That is a big bet on their philosophy.
Sonnet 4.6 is not going anywhere. For teams that need reliable, predictable output without surprises, it remains the workhorse. Opus 4.7 is for teams that have exhausted what Sonnet can do and need the next capability tier.
The question worth asking this week is whether your automation workflow is actually bottlenecked on model capability or on something else entirely. If it is the latter, a new model will not save you.
If it is the former, Opus 4.7 might be worth the switch. Just go in with eyes open about what you are trading.
Sources: Anthropic’s official Opus 4.7 announcement | HN Discussion


