Inference-time scaling is a groundbreaking shift in AI, moving away from mere size augmentation to sophisticated computational optimization during model inference. By allocating additional resources to think longer and deeper, AI models are now demonstrating unprecedented performance on complex reasoning tasks, marking a pivot towards a more nuanced and practical mode of AI development.
The Evolution of Inference-Time Scaling
In the landscape of artificial intelligence, a notable shift has been observed from the pursuit of ever-larger training regimes to a nuanced focus on enhancing large language models (LLMs) during inference time. This evolution is marked by the adoption of inference-time scaling techniques, which empower models to perform complex reasoning tasks more effectively. Among these, parallel sampling and the innovative concept of test-time compute stand out, laying the groundwork for significant advancements in AI reasoning capabilities. This chapter delves into how these techniques contribute to the development of advanced reasoning AI models, spotlighting breakthroughs exemplified by models such as DeepSeekMath-V2.
Parallel sampling, a technique integral to inference-time optimization, accelerates the processing capabilities of AI models. By enabling the simultaneous generation of multiple reasoning paths, this approach not only enhances computational efficiency but also enriches the model’s ability to explore a broader array of potential solutions. This is particularly crucial in complex reasoning tasks where the depth and breadth of inference play a pivotal role in achieving high precision. Through parallel sampling, models can sift through more hypotheses in a given time frame, significantly improving their problem-solving prowess.
On the other hand, the concept of test-time compute marks a revolutionary leap in AI performance optimization. This paradigm emphasizes extending the computational processing of models during inference, thereby allowing them to “think” longer and explore more reasoning tokens before arriving at a conclusion. Such an approach is instrumental in tasks that demand a high degree of cognitive depth, such as advanced mathematics or intricate language understanding. Test-time compute, by offering models the latitude to process information more thoroughly, paves the way for accuracy improvements that were previously unattainable within the constraints of traditional training methods.
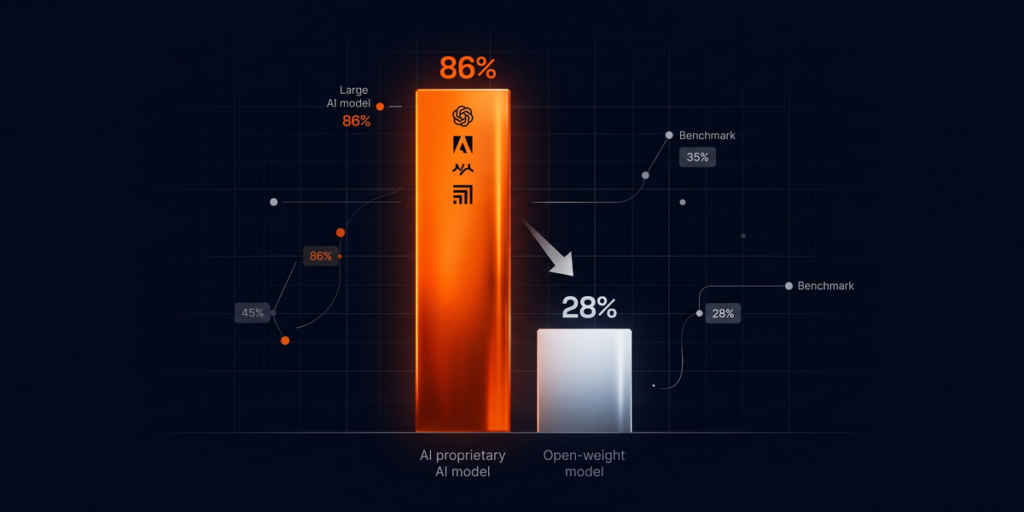
Recent breakthroughs, notably the success of models like DeepSeekMath-V2, underscore the efficacy of inference-time scaling in surmounting challenges posed by complex reasoning tasks. DeepSeekMath-V2, through leveraging extended inference capabilities, has achieved gold-level performance across rigorous benchmarks, heralding a new era in AI’s ability to handle advanced mathematical reasoning. This milestone not only showcases the potential of inference-time scaling but also signals a wider industry trend towards valuing precision and depth of reasoning in AI models.
The incremental latency and computational costs associated with inference-time scaling are balanced by the substantial gains in task-specific precision. Organizations are thus adopting a strategic approach to deploying these techniques, reserving heavy inference scaling for high-value, complex reasoning tasks. This careful consideration ensures that the benefits of enhanced precision outweigh the increased resource consumption, creating a sustainable model for AI development.
Moreover, the shift towards prioritizing inference-time efficiency signals a pragmatic reevaluation of performance enhancement strategies within the AI industry. By focusing on optimizing LLMs at inference time, researchers and developers are charting a course towards more intelligent, capable AI systems. Techniques such as parallel sampling and test-time compute not only enrich the model’s reasoning abilities but also exemplify the industry’s move towards more sophisticated and resource-aware approaches to AI development.
In essence, the evolution of inference-time scaling reflects a broader trend in the AI industry towards maximizing the cognitive capabilities of models while navigating the trade-offs between precision, latency, and computational costs. Through the adept application of techniques like parallel sampling and test-time compute, LLMs are being ushered into an era where their reasoning capabilities are dramatically enhanced, opening new frontiers in artificial intelligence. This strategic shift not only optimizes the deployment of these models across various domains but also signifies a pivotal moment in the journey towards realizing the full potential of AI reasoning.
Test-Time Compute: A Gateway to Advanced Reasoning
In the realm of artificial intelligence, the ability to perform advanced reasoning is a hallmark of the most sophisticated models. Key to unlocking this capability is an approach known as test-time compute, an innovative method focusing not just on the static capabilities acquired during training but on the dynamic expansion of these abilities during inference. This paradigm allows models to engage in what can be described as deeper thought processes, employing techniques such as dynamic planning, fine-tuning, and parallel sampling to push the boundaries of AI’s reasoning capabilities.
Dynamic planning in AI inference represents a strategic method where a model can adapt its computational strategies on the fly, prioritizing certain pathways or algorithms based on the demands of the task at hand. This method is particularly beneficial for tasks that require a nuanced understanding or complex problem-solving, as it allows the AI to “think ahead” and allocate resources more efficiently. By considering different potential outcomes or strategies in advance, the model can focus its computational power where it is most needed, thus enhancing its reasoning capabilities and performance on difficult tasks.
Fine-tuning during inference is another critical technique, allowing models to adjust their parameters slightly in response to the specific problem they are solving. This can be particularly useful for tasks that fall slightly outside the model’s initial training data, enabling it to adapt its understanding in real-time to better tackle the problem. This adaptability contributes to a model’s robustness against domain shifts, ensuring that its performance remains high even when faced with new or slightly altered tasks.
Parallel sampling, another key facet of inference-time computation, significantly enhances the model’s ability to process information and generate predictions or solutions. By considering multiple hypotheses or pathways concurrently, the model can compare and contrast different approaches more rapidly, leading to quicker, more accurate outcomes. This doesn’t just improve the model’s efficiency; it also increases the diversity of its problem-solving capabilities, allowing it to approach tasks from multiple angles and come up with more innovative solutions.
The application of these techniques has led to remarkable advancements in the field of AI. Models equipped with the ability to engage in test-time compute have demonstrated unparalleled performance in areas that require deep, logical reasoning and robustness in the face of unfamiliar tasks. As these models continue to evolve, they are setting new benchmarks for what AI can achieve, turning tasks that once seemed insurmountably complex into solvable problems.
However, the adoption of these advanced reasoning capabilities introduces new challenges, most notably in balancing the increased latency and computational costs against the improvements in task-specific precision. This trade-off is especially pertinent as inference costs continue to climb, with projections suggesting that they could account for up to 90% of a model’s lifecycle costs. As a result, organizations are compelled to make strategic decisions about where and how to deploy these powerful models, ensuring that they are reserved for the highest-value tasks where their exceptional reasoning abilities can be fully leveraged.
This strategic deployment underscores a broader shift in the AI field towards prioritizing inference-time efficiency and sophisticated tooling over simply scaling up training data and model size. By embracing the complexities of test-time compute, AI developers and researchers are opening up new avenues for the application of artificial intelligence, making strides towards models that can not only replicate but also expand upon human-like reasoning and problem-solving skills.
Striking the Right Balance: Latency vs. Precision
In the evolving landscape of artificial intelligence, the dynamism of inference-time scaling emerges as a pivotal force, propelling large language models like DeepSeekMath-V2 to tackle complex tasks with unprecedented precision. This leap forward underscores a paradigm shift—where the traditional emphasis on training scale gives way to a nuanced focus on the optimization of inference-time processes. This chapter delves into the intricacies of balancing latency against precision, a delicate act that organizations navigate as they deploy advanced reasoning AI models across varied applications.
The concept of “test-time compute” has heralded a new era in which accuracy enhancements are realized through prolonged inference periods. This method of extending computational processing allows AI models to generate additional reasoning tokens, thereby enhancing their capacity to resolve intricate problems. However, this performance boost comes at a cost, manifesting as increased latency and elevated computational expenses. As inference is anticipated to comprise 80–90% of AI model lifecycle costs, the trade-offs between latency and precision have catapulted to the forefront of strategic consideration for entities leveraging this technology.
Organizations are now tasked with navigating these trade-offs with strategic acumen. In high-stakes domains where precision is paramount, heavy inference scaling is judiciously applied to complex reasoning tasks. This approach, while resulting in higher latency, ensures that the models attain or even surpass desired levels of accuracy. On the flip side, in scenarios where immediacy is critical, or the tasks are less demanding, smaller or edge models are preferred. These models, though less powerful, are prized for their swift responses, thus catering to real-time or near-real-time requirements. This dichotomy exemplifies the strategic calibration organizations must undertake—weighing the necessity for precision against the imperative for speed.
Moreover, the year 2026 is earmarked as a turning point, signaling a collective shift towards prioritizing inference-time efficiency and the development of supporting tools over the brute-force approach of scaling training methods. This nuanced perspective champions a more pragmatic and sustainable approach to enhancing AI performance, whereby inference compute optimization becomes a central pillar in the strategic deployment of AI capabilities. Consequently, this strategic orientation not only acknowledges but also capitalizes on the inherent trade-offs between latency and precision, ensuring that AI deployments are both effective and efficient.
Within this framework, organizations are embarking on a meticulous journey of discovery, exploring various avenues to strike the optimal balance. For instance, deploying advanced reasoning AI models in domains like advanced mathematics or logic-intensive applications, where depth and accuracy of reasoning are non-negotiable, underscores the acceptance of higher latency as a worthwhile trade-off for gold-level performance. Conversely, in customer-facing applications where latency directly impacts user experience, a leaner, faster approach is employed, with models optimized for speed.
As we traverse further into the inference epoch, the strategies for managing these trade-offs continue to evolve. The following chapter will explore a range of inference compute optimization strategies, including model quantization, data batching, and hardware acceleration. Each of these strategies plays a critical role in enhancing performance, improving efficiency, and reducing costs, thereby enabling organizations to fine-tune their AI deployments for optimal outcomes. The meticulous balancing of latency versus precision, coupled with strategic deployment and optimization techniques, epitomizes the sophisticated landscape of modern AI utilization.
Inference Compute Optimization Strategies
Inference Compute Optimization Strategies represent a sophisticated blend of technical maneuvers and strategic decision-making pivotal for harnessing the computational power required by advanced reasoning AI models, such as those involved in inference-time scaling for large language models. As organizations navigate the intricate balance between latency and precision, elucidated in the previous chapter, the adoption of optimization strategies emerges as a crucial step towards enhancing performance gains, amplifying efficiency, and curtailing costs. This passage delves into the optimization techniques that are central to this endeavor, including model quantization, data batching, and hardware acceleration.
Model Quantization involves the process of converting a model’s weights from floating-point representation (which uses 32 or 64 bits) to lower precision formats like 8-bit integers. This seemingly simple reduction in numerical precision can lead to substantial decreases in both the memory footprint and computational requirements of deep learning models during inference. By compressing the model size without significantly sacrificing accuracy, organizations can deploy more sophisticated models on edge devices where computational resources are limited. The strategic use of quantization enhances the ability to perform heavy inference scaling on complex reasoning tasks directly at the source of data, thereby diminishing latency and operational costs.
Data Batching is another pivotal strategy for optimizing inference compute. By processing multiple instances of input data in parallel, rather than serially, the computational throughput can be significantly improved. This technique leverages the intrinsic parallel processing capabilities of modern hardware architectures, such as GPUs, to accelerate the inference phase. In practice, identifying the optimal batch size becomes a critical decision point, as too large a batch can increase latency due to the overhead of assembling and disassembling batches, while too small a batch fails to fully exploit the computational hardware’s potential. Striking the right balance in data batching is thus indispensable for maximizing inference efficiency, especially for models like DeepSeekMath-V2 that require extended reasoning time to achieve high precision on demanding tasks.
Hardware Acceleration involves the tailored use of specialized processors, such as Graphics Processing Units (GPUs), Tensor Processing Units (TPUs), and Field-Programmable Gate Arrays (FPGAs), to expedite specific types of computations commonly encountered in AI inference tasks. These hardware accelerators can provide orders of magnitude improvements in processing speed for the matrix multiplications and vector operations that are ubiquitous in deep learning. By architecting the inference pipeline to leverage these hardware capabilities effectively, organizations can achieve dramatic reductions in inference time, facilitating the deployment of more computationally demanding AI models within acceptable latency constraints. The synergy gained from coupling hardware acceleration with software optimization techniques like quantization further amplifies the performance and efficiency gains.
Together, these strategies form a comprehensive suite of tools for organizations to refine the inference compute capabilities of their AI systems. By optimizing the model architecture through quantization, strategically managing data flow with batching, and exploiting hardware accelerations, it becomes feasible to not only meet the computational demands of advanced reasoning tasks but to do so in a manner that is both cost-effective and latency-conscious. As highlighted in the forthcoming chapter, the continuous evolution of these techniques is expected to play a central role in shaping the future landscape of inference-time efficiency in AI, pushing the boundaries of what is achievable with large language models and heralding a new era of computational intelligence optimization.
The Future of Inference-Time Efficiency
In the evolving landscape of artificial intelligence, the paradigm shift towards inference-time scaling represents a beacon for the future of AI model efficiency. As the previous chapter outlined various strategies for optimizing inference compute, such as model quantization and hardware acceleration, we delve deeper into the burgeoning domain of test-time compute. This new frontier emphasizes not just the optimization of models for faster computation but the strategic extension of computational capacity at inference time to bolster reasoning capabilities, particularly in advanced reasoning AI models.
The transition towards focusing on inference-time scaling over sheer model size expansion is underscored by the groundbreaking advancements in models like DeepSeekMath-V2. These models harness the power of generating additional reasoning tokens during inference, enabling them to dissect and interpret complex, high-level tasks with unprecedented accuracy. Such models exemplify the burgeoning concept of trading off increased latency and computational costs for significant precision gains on tasks requiring intricate reasoning, such as advanced mathematics or complex language understanding.
However, this boost in performance does not come without its economic considerations. As inferred from the latest trends, the test-time compute paradigm suggests that accuracy improvements stemming from prolonged inference sessions might see inference costs ballooning to represent 80–90% of the entire lifecycle costs of AI models. This shift necessitates a nuanced understanding of cost-benefit analysis, where organizations need to strategically balance the latency costs incurred from heavy inference scaling against the precision gains on high-value, complex reasoning tasks. This balancing act encourages the deployment of advanced reasoning AI models in scenarios where the value derived from precision outweighs the increased time and computation expenditure.
Furthermore, in response to this economic dynamic, there’s a marked trend towards prioritizing inference-time efficiency and tooling. This trend highlights a pragmatic approach to AI performance enhancement, shifting the focus from simply enlarging models through training to refining and extending their inference capabilities. Such an approach is not only about enhancing model intelligence but also about doing so in a economically viable manner. Organizations are increasingly deploying smaller or edge models for routine tasks to maintain operational speed and cost efficiency, reserving the deep, computationally intensive inference processes for tasks where advanced reasoning is paramount.
Looking ahead, we foresee a continuum of development in the tools and techniques designed to optimize inference-time efficiency. Innovations in hardware, such as more powerful and energy-efficient processors, alongside advances in software, including more sophisticated model compression and optimization algorithms, will play pivotal roles in this evolution. As AI models become even more integral across sectors, the demand for models that can not only think deeply but do so efficiently and cost-effectively will surge.
The future landscape of inference-time efficiency in AI models is poised to be shaped by these new scaling paradigms and economic considerations. As organizations navigate this terrain, the strategic deployment of AI models—balancing high-value reasoning tasks against the imperative for speed and cost efficiency—will be crucial. This calls for a sophisticated understanding of not just AI technology and its capabilities but of the broader economic and operational contexts in which these models operate. The era of inference-time scaling is not just about making AI models more intelligent; it’s about doing so in a way that is sustainable and aligned with broader business and societal goals.
Conclusions
In the age of advanced reasoning AI, inference-time scaling embodies a strategic response to rising computational demands, prioritizing precision and cost-effectiveness. As we navigate the trade-offs of latency and performance, the future focuses on optimizing inference, architecting a new era of smarter and more efficient AI.