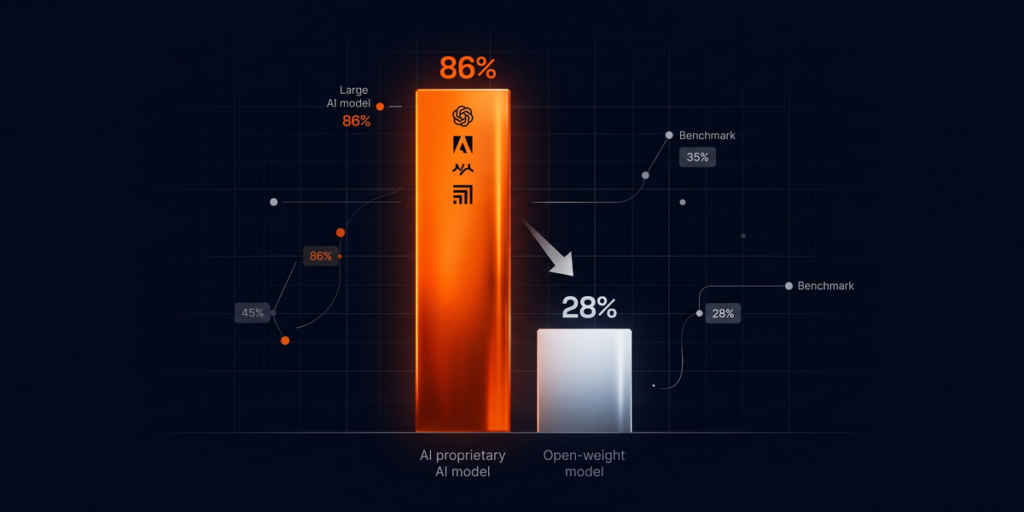
Facing a critical depletion of traditional AI training data by the end of 2025, synthetic data generation emerges as a beacon of hope. This technology empowers numerous industries to create extensive, high-quality datasets, propelling advancements in drug discovery, finance, manufacturing, and beyond.
The Rise of Synthetic Data in Addressing AI Training Shortages
The Rise of Synthetic Data in Addressing AI Training Shortages
The advent of artificial intelligence (AI) and its insatiable appetite for data has ushered in a new era of innovation across various sectors. From drug discovery and finance to manufacturing, the ability to analyze vast datasets and draw insightful conclusions is transforming traditional practices. However, this data-driven revolution faces a critical bottleneck: the looming shortage of traditional AI training data expected by December 2025. As the variety and volume of available data fail to meet the ever-growing demands, synthetic data generation emerges as a lifeline, offering a sustainable and versatile solution.
One of the key drivers behind the burgeoning demand for synthetic data is its unparalleled capacity to provide diverse, extensive, and highly realistic datasets. Unlike traditional datasets, which can be limited in scope and subject to privacy concerns, synthetic data allows for the generation of information that closely mimics real-world complexity without compromising confidentiality. This feature is particularly vital given the expected depletion of traditional data sources, pushing industries to seek out innovative methods to fuel their AI models.
Generating synthetic data involves sophisticated techniques that blend physical simulations with generative AI technologies. This hybrid approach ensures the production of labeled, high-fidelity datasets tailored to specific domain requirements. For instance, in drug discovery, synthetic patient records and virtual biological models can simulate the effects of potential treatments, providing invaluable insights long before clinical trials commence. This not only accelerates the research process but also significantly reduces the financial and ethical risks associated with early-stage human trials.
In the financial sector, synthetic market data allows for the stress-testing of investment portfolios against a range of hypothetical scenarios, from economic downturns to geopolitical crises. This capability is crucial for developing resilient strategies that can withstand unpredictable market behaviors. Similarly, in manufacturing, synthetic data facilitates the virtual screening of materials and catalysts, enabling the discovery of new compounds without the time and expense of traditional lab experimentation.
The techniques for generating synthetic data are diverse, ranging from simple data augmentation methods that expand existing datasets through variation, to complex Generative Adversarial Networks (GANs) that can create entirely new data instances indistinguishable from real data. Regardless of the method, the goal remains the same: to produce realistic, structured data that can train AI models effectively. This approach not only addresses the immediate challenges posed by data scarcity but also opens up new avenues for innovation and exploration across industries.
Crucially, synthetic data generation offers a level of control and flexibility not possible with traditional data. Researchers and developers can simulate edge cases and rare events, enhancing the robustness and accuracy of AI models. This is particularly important in fields like autonomous driving, where training AI systems to handle unlikely but potentially dangerous road scenarios is essential. By enabling these controlled experiments, synthetic data helps ensure that AI systems can act reliably and safely in the real world.
As we stand on the brink of a potential data drought, the shift towards synthetic data generation represents not just a temporary workaround but a strategic reorientation towards enduring, scalable solutions. By harnessing the power of synthetic data, industries can unlock the infinite potential of AI, pushing the boundaries of what is possible and ensuring that the pace of innovation remains unabated in the face of data scarcity.
Revolutionizing Drug Discovery with Virtual Models and Synthetic Patients
The transformative impact of synthetic data in the arena of drug discovery is a testament to the innovative strides being taken to advance medical science. Leveraging virtual models and synthetic patient records signifies a paradigm shift, a move towards in-silico experimentation that marks an era of reduced costs and minimized risks traditionally associated with drug development. The utilization of synthetic data to predict clinical outcomes before actual trials holds the potential to revolutionize the pharmaceutical industry by streamlining the drug discovery process while ensuring efficacy and safety.Synthetic patient records, generated through advanced algorithms and generative AI, offer a rich, diverse dataset that mimics real-world populations. These datasets include a wide range of variables such as genetic information, disease progression indicators, and patient responses to treatments. By utilizing these records, researchers can conduct virtual trials, testing the effects of new drugs on varied patient groups without the ethical and logistical complexities of real-world clinical trials. This not only accelerates the research phase but also significantly cuts down on the financial outlay required for extensive clinical trials, ultimately leading to faster drug development cycles and reduced time-to-market for vital medications.Virtual biological models take this concept a step further by simulating the physiological and molecular interactions that occur in response to a drug. These models can predict how different drugs might interact with various biological pathways, providing valuable insights into efficacy and potential side effects early in the drug development process. By simulating the complex dynamics of human biology, researchers can refine drug formulas before they reach the costly phase of clinical trials, thereby lowering the risk of late-stage failures.The synthesis of these virtual models and synthetic datasets relies on a hybrid approach that blends data from physical simulations and generative AI. This synergy enables the creation of high-fidelity, labeled datasets that reflect the multifaceted nature of human biology and disease. Such datasets are instrumental in conducting controlled experiments and training AI models to identify promising drug candidates much earlier than conventional methods would allow.Furthermore, the application of synthetic data in drug discovery extends beyond the initial phases of identifying and validating potential drugs. It also plays a critical role in predicting patient adherence and drug administration strategies, thus encompassing the full spectrum of the drug development pipeline. This holistic approach ensures that the drugs not only reach the market swiftly but also cater to the nuanced needs of diverse patient populations.In an industry where the stakes are inherently high, and the costs of failure immense, the shift towards synthetic data and virtual models presents a prudent and visionary approach to drug discovery. It not only addresses the imminent data scarcity but also aligns with the broader goal of personalized medicine, ensuring that the future of healthcare is both innovative and inclusive.As the pharmaceutical industry continues to navigate the challenges of developing effective, safe drugs within compressed timelines, synthetic data emerges as a beacon of hope. It represents a new frontier in drug discovery, where virtual experiments and synthetic patient records pave the way for groundbreaking advancements in medical science. With the potential to reduce costs, mitigate risks, and accelerate the delivery of life-saving drugs to the market, the role of synthetic data in drug discovery is poised to expand, transforming the landscape of medical research in the process.
Synthetic Data in Finance: A New Era of Market Simulations and Stress Testing
Building on the momentum from the application of synthetic data in the pioneering field of drug discovery, the financial sector is harnessing the power of synthetic market simulations to usher in a new era of risk assessment and management. These technological advancements offer a novel approach to financial modeling, enabling institutions to stress-test their portfolios against unprecedented crisis scenarios. The advent of large quantitative models and the generation of synthetic data are providing robust solutions to the previously insurmountable challenges of data shortage and variety in AI training.
Financial markets are inherently volatile and subject to a wide array of influences, from geopolitical events to sudden shifts in economic policies. Traditional data sources and modeling techniques often fall short in capturing the full spectrum of potential events, especially those categorized as “black swan” events. By generating realistic, yet entirely novel, market data, synthetic simulations allow financial institutions to probe the depths of market behavior under crisis conditions not previously recorded. This capacity to model complex, interwoven scenarios goes beyond historic data analysis, offering a more dynamic tool for assessing potential vulnerabilities and systemic risk exposures.
The robustness of synthetic data in finance lies in its ability to create high-fidelity, diverse scenarios that reflect possible future market conditions. This is particularly important for stress testing, where the goal is to understand how different aspects of the financial system would perform under extreme but plausible conditions. Traditional stress testing methods often rely on repurposing historical data, which may not fully encapsulate future complexities. Synthetic data, on the other hand, is generated through algorithms that can incorporate a broader set of variables and outcomes, making stress tests more comprehensive and forward-looking.
Moreover, the use of synthetic data in financial modeling facilitates a more nuanced exploration of “what-if” scenarios. This is achieved by employing generative AI in combination with financial theories and models to simulate a range of outcomes based on varying assumptions. Through this process, financial institutions can identify potential risks and weaknesses in their portfolios that might not be visible through conventional analysis. For example, synthetic market simulations can model the impact of a sudden change in interest rates on a global scale or the ripple effects of a default in a major economy. This kind of granular, scenario-based analysis is pivotal in crafting more resilient financial strategies and investment portfolios.
In addition to enhancing risk management practices, synthetic data holds promise for regulatory compliance and operational efficiency within the financial sector. Regulators are increasingly looking for more sophisticated and predictive models of financial stability. The comprehensive nature of synthetic data-driven stress testing can provide a more accurate assessment of systemic risks, aiding in the formulation of more effective regulatory policies. On the operational side, the ability to generate and use synthetic data streamlines the process of model validation and testing, reducing the time and resources required for these essential activities.
The integration of synthetic data into the financial sector marks a significant step towards a more predictive, rather than reactive, approach to financial management. By enabling institutions to navigate the complexities of modern financial systems with greater precision and understanding, synthetic market simulations stand at the forefront of financial innovation. This progression aligns seamlessly with the broader industry trend of utilizing synthetic data and large quantitative models to address the acute challenges of traditional AI training data scarcity, as witnessed in other domains such as drug discovery and manufacturing.
As we delve into the next chapter, the focus shifts to manufacturing, where advanced physics and atomistic simulations are leveraging synthetic data to revolutionize the development of new materials and the optimization of production processes. This continuous thread of innovation across sectors underscores the transformative power of synthetic data, paving the way for groundbreaking advancements in AI applications and beyond.
Fostering Innovations in Manufacturing with Synthetic Simulations
Fostering Innovations in Manufacturing with Synthetic Simulations
The manufacturing sector is undergoing a profound transformation, driven by the advent of synthetic data generation and large quantitative models. As we navigate through the digital era, the traditional methods of material discovery and process optimization in manufacturing are being outpaced by the capabilities offered by advanced physics and atomistic simulations. These cutting-edge technologies are reshaping the landscape of manufacturing, enabling the creation of new materials and the optimization of processes in ways that far exceed the capabilities of conventional laboratory methods.
At the heart of this revolution lies the use of synthetic data – an innovative solution to the imminent shortage of traditional AI training data. Through synthetic data generation, manufacturers can now rely on vast, structured, and hyper-realistic datasets. These datasets are instrumental in conducting virtual experiments that push the boundaries of material science and engineering. By employing a blend of advanced computational models and generative artificial intelligence, these simulations generate high-fidelity data that mirrors real-world physical properties and behaviors. This synergy enables the exploration of countless scenarios and variables in a fraction of the time and cost required for physical prototyping and testing.
One of the most promising applications of synthetic data in manufacturing is in the domain of material discovery. Through the use of atomistic simulations, scientists and engineers can virtually model the behavior of materials at the atomic and molecular levels. This allows for an accurate prediction of material properties, such as strength, durability, and electrical conductivity, before any real-world synthesis. Such capabilities are paramount in industries where material performance is critical, including aerospace, automotive, and electronics. By leveraging synthetic data, these industries can dramatically accelerate the discovery and deployment of next-generation materials that meet exacting requirements.
Moreover, synthetic simulations play a crucial role in optimizing manufacturing processes. Advanced physics simulations offer unprecedented insight into the mechanics of manufacturing techniques, from casting and molding to additive manufacturing. By modeling these processes in virtual environments, engineers can identify inefficiencies, predict potential failures, and explore corrective measures without the expense and risk associated with trial-and-error in physical settings. This approach not only enhances the reliability and efficiency of manufacturing processes but also fosters innovation by allowing the exploration of unconventional methods and materials.
The use of synthetic data in manufacturing also aligns with the growing emphasis on sustainability. By predicting material behaviors and process outcomes with high accuracy, manufacturers can minimize waste and maximize energy efficiency. This predictive capability, coupled with the ability to experiment virtually, ensures that resources are utilized judiciously, supporting the industry’s transition towards greener and more sustainable practices.
As the manufacturing sector continues to evolve, the fusion of synthetic data generation with advanced physics and atomistic simulations is setting a new standard for innovation. This transition not only addresses the critical challenge of data scarcity but also opens the door to a future where virtual experiments drive the rapid discovery of materials and the optimization of manufacturing processes. By harnessing the infinite potential of synthetic data, manufacturers are poised to unlock efficiencies, foster innovation, and achieve competitive advantages in an increasingly complex and fast-paced global market.
The next chapter will delve into the significance of hybrid approaches in the creation of synthetic data. These approaches, which blend physical simulations with generative AI, are pivotal in generating datasets that are not only rich in volume but also unparalleled in fidelity. This convergence is crucial for enabling controlled experiments and comprehensive training of AI models across various industries, heralding a new era of precision and innovation in the use of synthetic data.
Hybrid Approaches: The Next Frontier in High-Fidelity Synthetic Data
In the rapidly evolving landscape of artificial intelligence (AI), the advent of hybrid approaches merging physical simulations with generative AI stands out as a groundbreaking development, especially in concocting high-fidelity synthetic data. This innovative blend not only surmounts the impending doom of traditional AI training data shortage, projected to reach a critical point by December 2025, but also propels the capabilities of AI across various domains, ensuring the generation of robust, realistic datasets essential for controlled experiments and comprehensive edge-case scenario training.
The essence of these hybrid approaches lies in their ability to harness the predictive precision of physical simulations alongside the creative power of generative AI models. Physical simulations, grounded in the laws of physics and chemistry, generate data that mirrors the complexity and variability of the real world with remarkable accuracy. When combined with generative AI algorithms – capable of learning and mimicking any data distribution – the resultant synthetic data sets are not only vast but also encompass a wide spectrum of possible outcomes, thereby significantly enhancing the depth and breadth of training data available for AI models.
In the context of drug discovery, this synergy between physical simulations and generative AI has proven to be a boon. Synthetic patient records and virtual biological models are being cultivated with unparalleled precision, enabling researchers to predict clinical outcomes with greater accuracy before actual trials commence. This not only mitigates the risks associated with human trials but also drastically reduces the time and cost involved in bringing a new drug to market. By generating endless permutations and combinations of molecular structures and their interactions, these hybrid approaches facilitate the exploration of therapeutic possibilities that would have been deemed improbable or impossible with traditional research methods.
Shifting to the financial industry, the application of these hybrid models is revolutionizing the way institutions prepare for potential crises. Through the generation of synthetic market data that realistically simulates various economic and financial scenarios, including extreme crisis situations, financial models can now be stress-tested more thoroughly. This enhancement in predictive analytics allows for the anticipation of market movements and systemic behaviors that were previously beyond the scope of traditional risk management strategies, thereby fortifying the financial sector against unforeseen global shocks.
Moreover, in the realm of manufacturing, where the previous chapter detailed the incredible strides made through synthetic simulations in material discovery and process optimization, the infusion of generative AI into physical simulations elevates these advancements further. By enabling the virtual screening of countless new materials with designed properties, these hybrid models expedite the discovery and development of next-generation materials and manufacturing processes. This not only accelerates innovation but also contributes to a more sustainable manufacturing paradigm by minimizing waste and optimizing energy usage.
At its core, the fusion of physical simulations with generative AI embodies a powerful tool for generating labeled, high-fidelity datasets across a myriad of domains. This convergence facilitates controlled experiments and the training of AI models on edge-case scenarios without the ethical, financial, and physical constraints often associated with real-world data collection. As industries continue to grapple with the burgeoning demand for high-quality, diverse datasets, these hybrid approaches offer a glimmer of hope, promising an era of limitless synthetic data generation that could very well be the key to unlocking the infinite potential of AI.
With the groundwork laid by these pioneering synthetic data generation techniques, the stage is set for the next chapter in our exploration of AI’s boundless potential across industries. As we delve deeper into the intricacies of applying these state-of-the-art datasets to actual problem-solving scenarios, the transformative power of synthetic data in shaping the future of AI becomes increasingly evident, heralding a new era of innovation and discovery.
Conclusions
Synthetic data generation offers an innovative and solution-focused approach to the impending crisis of data scarcity for AI training. Looking ahead, these technologies will continue to enable groundbreaking virtual experimentation and drive progress across various industries.