The GPU memory wall has been the gatekeeper for serious LLM training since the beginning. If your model does not fit in VRAM, you need more GPUs, more money, more infrastructure. MegaTrain just made that wall optional for a lot of teams.
A paper dropped on arXiv on April 6 and the HN front page picked it up today with 294 points and climbing. The core claim is simple to state: store parameters and optimizer states in host CPU memory instead of GPU VRAM. Stream them to the GPU for each layer’s computation. Offload gradients back to host. Repeat. On a single H200 with 1.5 terabytes of host memory, you can reliably train 120 billion parameters at full precision.
That is not a benchmark claim for an idealized scenario. It is a reproducible result.
How It Works Technically
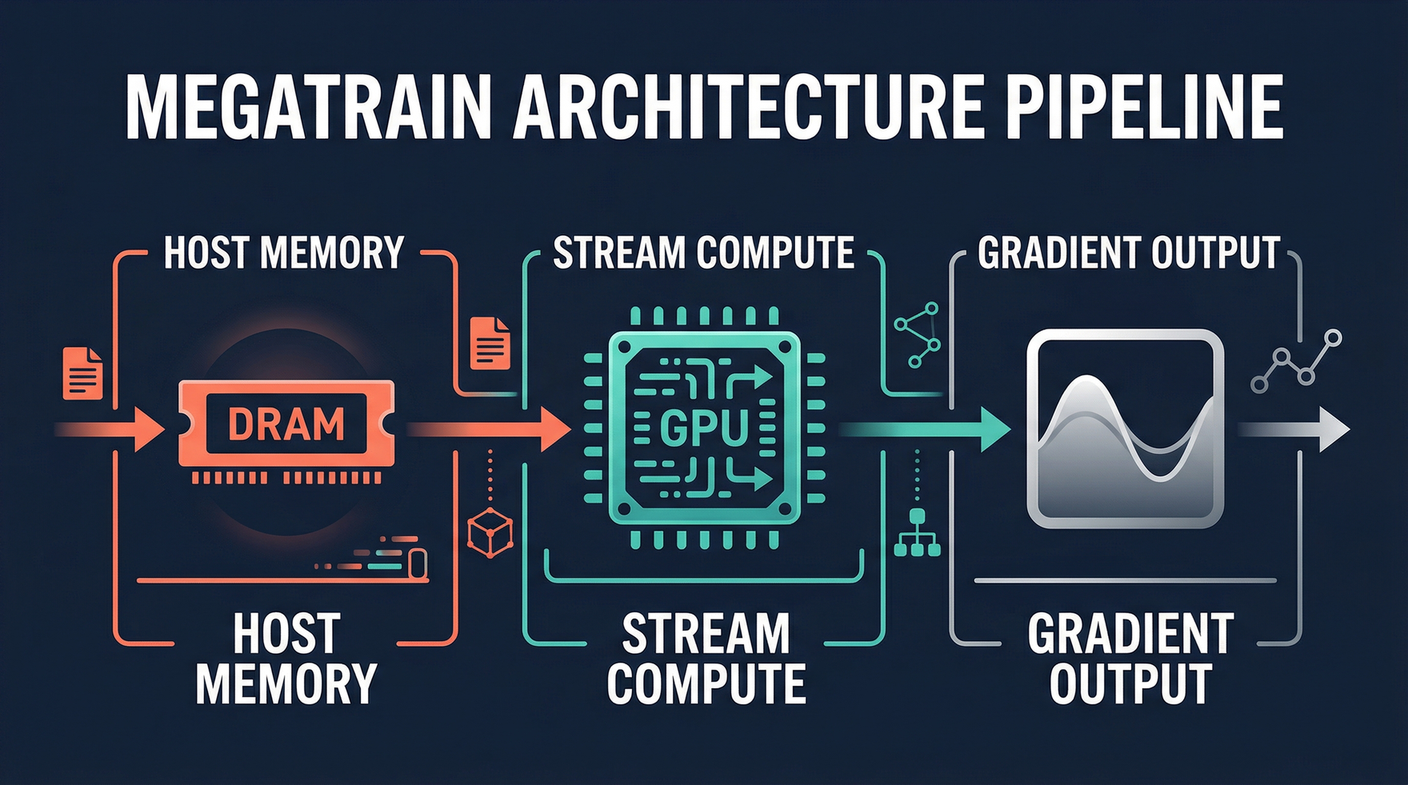
The traditional approach keeps parameters in GPU VRAM. This is fast but limits you to what fits on the card. MegaTrain flips the assumption. Host memory holds everything. The GPU is a transient compute engine that receives parameters, does the math, and sends gradients back.
The bottleneck is obvious. CPU to GPU bandwidth is slower than GPU VRAM bandwidth. MegaTrain addresses this with a pipelined double-buffered execution engine. Multiple CUDA streams overlap three operations: parameter prefetching, layer computation, and gradient offloading. While one batch is being computed, the next layer’s parameters are already being loaded. The pipeline keeps the GPU fed continuously instead of waiting for each step to finish before starting the next.
They also replaced persistent autograd computation graphs with stateless layer templates. Weights get bound dynamically as they stream in. This eliminates the overhead of maintaining persistent graph metadata across large models while preserving the scheduling flexibility that makes autograd useful. The stateless approach is cleaner for this streaming use case.
The Numbers
On a single H200 with 1.5 terabytes of host memory, MegaTrain trains up to 120 billion parameters reliably. That is the headline number.
For smaller models, the story is equally interesting. On a single GH200, MegaTrain trains a 7 billion parameter model with a 512k token context. That long-context capability previously required multi-GPU setups. Researchers studying how models behave at very long contexts now have a single-machine path to explore that.
The throughput comparison against DeepSpeed ZeRO-3 is the number that matters for teams already using distributed training. On 14 billion parameter models, MegaTrain achieves 1.84x the throughput of ZeRO-3. It is not just enabling larger models than your hardware budget would suggest. It is faster per GPU for comparable sizes.
Who This Actually Helps
If you are a research team or a small company that has been priced out of large model training by GPU cluster costs, this changes your options. You still need the H200 and you still need 1.5 terabytes of host memory. Those are not free. But they are one machine instead of a coordinated cluster. The infrastructure difference is real.
For enterprise infrastructure teams, the same logic applies before you buy another 8-GPU node. MegaTrain shows that host-memory-based training is viable up to 120 billion parameters and faster per GPU than CPU-offloaded ZeRO-3 at smaller scales. Your next training run may be cheaper than your last one if you have the host memory available.
The democratization implication is real but bounded. A 1.5 terabyte H200 is not a desktop machine. The ceiling for what this approach enables is still high. The floor has moved.
Sources:
– MegaTrain Paper (arXiv)
– Hacker News Discussion